
Para los que no sepan: El programa AlphaGo desarrollado por una subsidiaria del monstruo de la comunicación por internet Google, venció finalmente a Sedol Lee Gran Maestro de Go. Y ya puedo ver sus expresiones de: “…¿Y qué?” Bueno, déjenme explicar. El hecho que AlphaGo haya ganado es sumamente significativo porque es el primer paso concreto hacia la inteligencia artificial. Tal vez pueda tener un buen oponente cuando juegue Agricola en la compu…
CONTEXTO: El juego de Go
 El juego de Go, llamado también Baduk, tiene sus orígenes en China. Hace 2,500 años la gente de Asia empezó a jugarlo, y más importante aún, empezó a tratar de descifrarlo. Las reglas del juego son, como todo buen juego abstracto, bastante simples.
El juego de Go, llamado también Baduk, tiene sus orígenes en China. Hace 2,500 años la gente de Asia empezó a jugarlo, y más importante aún, empezó a tratar de descifrarlo. Las reglas del juego son, como todo buen juego abstracto, bastante simples.
En el Go eres un gran rey que trata de agrandar su territorio conquistando el territorio del otro rey. Para esto utiliza sus ejércitos, colocándolos uno tras otro para invadir, rechazar y salvaguardar lo ganado. Esto esta abstraído de la siguiente forma:
Cada jugador tiene un color de piedras, las hay en negro y blanco. El jugador que utilice las piezas negras irá primero. El pondrá una piedra en la encrucijada de un tablero con una cuadrícula de 19 x 19 (hay cuadrículas más pequeñas, pero hey… ¡Vive a lo grande o muere!) una a la vez. Cada piedra goza, si está sola de 4 libertades (para continuar con el tema bélico: libertad de abastecimiento) hechas por las líneas que van hacia ella. Si el contario pone una piedra a la par de la primera, ambas tendrán 3 libertades. Si alguna vez tu piedra se queda sin libertades, pierdes ese ejército y el contrario gana ese territorio.
 Hay unas cuantas reglas más, pero no son relevantes para el artículo actual. Si quieren saber más de este juego les recomiendo estos videos muy buenos.
Hay unas cuantas reglas más, pero no son relevantes para el artículo actual. Si quieren saber más de este juego les recomiendo estos videos muy buenos.
¿PORQUÉ ES TAN DIFÍCIL PARA LAS COMPUTADORAS JUGAR GO?
OK, acá es donde se pone un poco escabrosa la cosa. Hasta el desarrollo de Deep Blue, la computadora que derrotó a Kasparov en Ajedrez, el problema se había enfrentado tratando de resolver para todas las combinaciones de movimientos cuál sería la movida ganadora. Esto se llama: resolver por medio de Fuerza Bruta.
Esta aproximación al problema se hace por medio de un árbol de búsqueda. Para simplificarlo, vi un ejemplo que me pareció bastante alentador descrito por Robert Miles, estudiante de doctorado de la universidad de Nottingham:
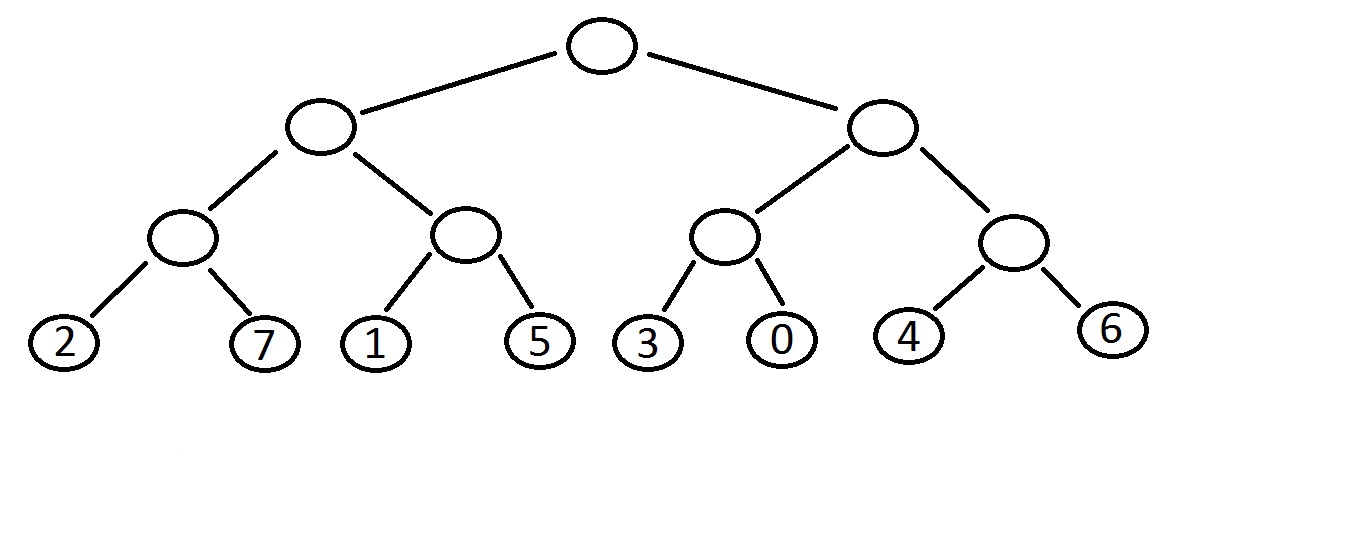 Este es un juego bastante simplificado. Este es un juego para dos jugadores en donde uno quiere obtener el número más alto al final del juego y el otro el número más bajo. Empezando por el globo de hasta arriba, el primer jugador decide si quiere ir a la derecha o a la izquierda. El segundo jugador, desde esa nueva posición decide si quiere ir a la derecha o a la izquierda.
Este es un juego bastante simplificado. Este es un juego para dos jugadores en donde uno quiere obtener el número más alto al final del juego y el otro el número más bajo. Empezando por el globo de hasta arriba, el primer jugador decide si quiere ir a la derecha o a la izquierda. El segundo jugador, desde esa nueva posición decide si quiere ir a la derecha o a la izquierda.
Esta es una simplificación de la clase de la conceptualización de los juegos en general. Eso es, tomas una decisión que te ayuda a ti y beneficia en menor grado a tu contrincante. Entonces en este simple juego, para evaluar el valor de cada movida, podemos comenzar desde el final. Al primer jugador le conviene más el 7 que el 2 en la primera pareja del último ramal. Por lo tanto podremos ponerle al entronque un valor de 7 (porque eso es lo que quiere obtener el jugador número 1). En la siguiente pareja entre 1 y 5 el primer jugador elegiría 5, entonces el entronque le ponemos valor de 5 y así sucesivamente.
 Es así como las computadoras solían evaluar las movidas del ajedrez. Asignándole valores a cada una de las movidas partiendo, no desde una posición final (eso tomaría una cantidad de tiempo absurdo), sino partiendo de las medidas más ventajosas para un jugador por sobre su oponente. Entonces en el tablero de ajedrez la máquina le asigna un valor de 8 a la reina, 1 al peón y así puede deducir si el tablero beneficia a uno u a otro jugador.
Es así como las computadoras solían evaluar las movidas del ajedrez. Asignándole valores a cada una de las movidas partiendo, no desde una posición final (eso tomaría una cantidad de tiempo absurdo), sino partiendo de las medidas más ventajosas para un jugador por sobre su oponente. Entonces en el tablero de ajedrez la máquina le asigna un valor de 8 a la reina, 1 al peón y así puede deducir si el tablero beneficia a uno u a otro jugador.
Eso está bien si pensamos que en ajedrez la cantidad de ramas (o como dicen los ingenieros: Factor de ramificación) es decir la cantidad de círculos que tenemos que dibujar abajo del primero son sólo 35, cada una de estos 35 tiene a su vez 35 más.
Pero qué hay con Go? Cada una de sus movidas tiene 250 círculos abajo del primero y cada una tiene 250 más.
COMO FUNCIONA ALPHA GO

Ok, si quieres hacer la diagramación de todas las ramas de decisión que habría que analizar para resolver GO, necesitarías un montón de papel… eh… y un universo más grande. Entonces, si la fuerza bruta no es suficiente para resolver el problema, los ingenieros de Deep Thought (42!) tuvieron que tomar un nuevo camino.
Deep Thougth combinó dos métodos para motivar a su sistema a “aprender”. El primero es Aprendizaje por esfuerzo autónomo y el segundo Aprendizaje profundo.
Según el experto Brais Martinez, el aprendizaje por esfuerzo autónomo es cuando al que aprende no le dices exactamente cuál es el resultado que quieres que obtenga sino sólo le dirás cuál es la tarea que quieres que realice y de vez en cuando le dices: “si, ahí vas bien”. Esto suena un poco enredado, pero es bastante sencillo: Si en vez de decirle a un niño que 3 + 8 es 11, le dices ok, quiero que hagas una suma, la suma se hace así: 1 + 1 igual a 2, 2+1=3, vas bien… ¡Super!… 3+1=4, 4+4=8, y eventualmente llegará a la solución del problema que quieres que solucione.

En el caso de AlphaGo, los ingenieros utilizaron el concepto de Aprendizaje profundo. Ellos crearon dos algoritmos (instrucciones que utiliza una computadora para encontrar el resultado a un problema) con diferentes parámetros y los pusieron a jugar GO. Cada vez que uno ganaba, guardaban el parámetro y lo hacían jugar en contra de otros algoritmos. El resultado de uno de estos procesos entonces, se convierte en los datos de inicio del siguiente proceso. De ahí el adjetivo de “Profundo” porque cada nivel de producto da lugar a un nivel más profundo de aprendizaje.
Así, los ingenieros tienen un sistema que almacena 30 millones de posiciones (el juego de GO es marcado por el reconocimiento de patrones, no por el valor de cada movida individual) y dejó que otro sistema jugara en contra de estos datos iniciales cuando gana el sistema, este resultado se almacena. Al principio AlphaGo podía reconocer una formación ganadora 57 por ciento de las veces nada más. Pero con el tiempo mejoró.
El sistema completo de Alpha Go consta entonces de 3 sistemas individuales: Uno es el que aprende jugando en contra de sí mismo, el otro decide el valor de cada jugada dependiendo del resultado del primero y el tercero: media entre los dos para tomar una decisión
El proceso que realiza Alpha Go es tan rápido que los creadores no están seguros cómo es que juega. Como no comenzó con ciertos lineamientos, sino que la computadora aprendió a jugar sola, los expertos no saben realmente cómo llega a las conclusiones que le llevan a tomar un movimiento sobre otro.

Ahora para dejarles ya… Esta computadora que aprende lo hace de una forma que los seres humanos no comprenden, por lo tanto, habían jugadas durante el match con Sedol Lee que intrigaban a todos los presentes. Pero es porque no aprendió de la misma manera que todos los grandes maestros humanos actuales.
La pregunta más importante realmente es ¿Para qué diseñar una computadora que aprende? Esto me mantiene despierto más que preguntarme si voy a poder jugar un buen partido de Agricola en contra de la compu…
Eso es todo por hoy, ¿Ustedes qué piensan de la inteligencia artificial? hay un libro muy bueno que me gustaría recomendar: Superintelligence: Paths, dangers, stragegies de Nick Bostrom. Este es un libro en donde se discute la dificultad de controlar la inteligencia artificial cuando esta se desarrolle. También escuchen el episodio 52 de HI (no es de juegos, pero es muy bueno el podcast)
Bibliografía:
videos: https://www.youtube.com/watch?v=5oXyibEgJr0, https://www.youtube.com/watch?v=qWcfiPi9gUU&nohtml5=False
https://googleblog.blogspot.com/2016/01/alphago-machine-learning-game-go.html
http://www.wired.com/2016/01/in-a-huge-breakthrough-googles-ai-beats-a-top-player-at-the-game-of-go/
http://blog.ruslans.com/2015/07/prime-factorization-elms.html
